IRT omfatter en række metoder til at udvikle målemetoder (tests).
IRT beskæftiger sig med kategoriale data, som “ja/nej”, “rigtigt/forkert”, og efterhånden er også udviklet IRT-metoder til at håndtere ordinale data med flere svarmuligheder, f.eks. “helt uenig” = 0, “uenig” = 1, “enig” = 2, “helt enig” = 3.
Udviklingen af metoderne foregik samtidig og uafhængigt af hinanden af en amerikansk retning og af den danske statistiker Georg Rasch. Udviklingen foregik også samtidig og uafhængigt med udviklingen af faktoranalysen, som beskæftigede sig med kontinuerte data.
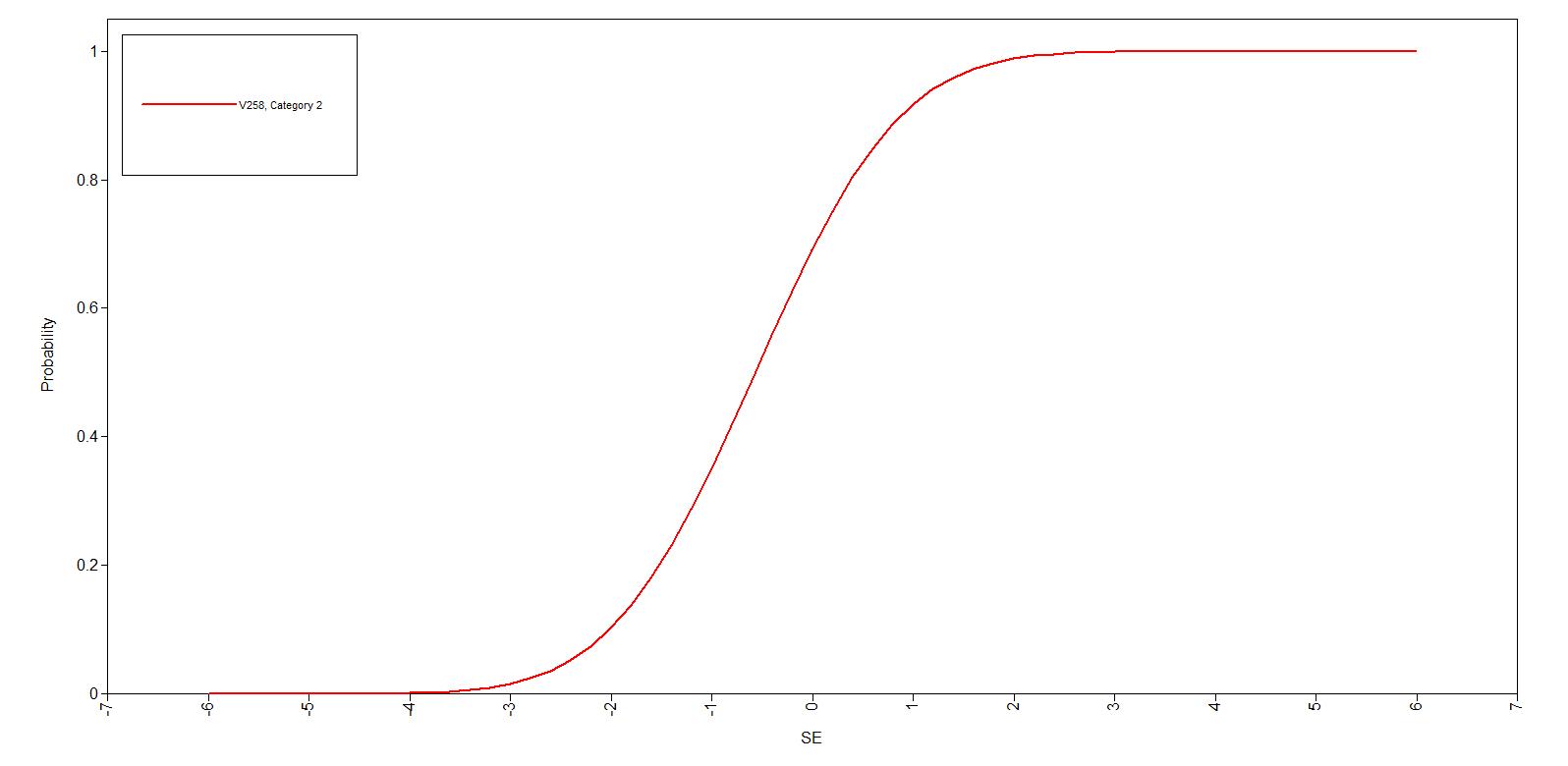
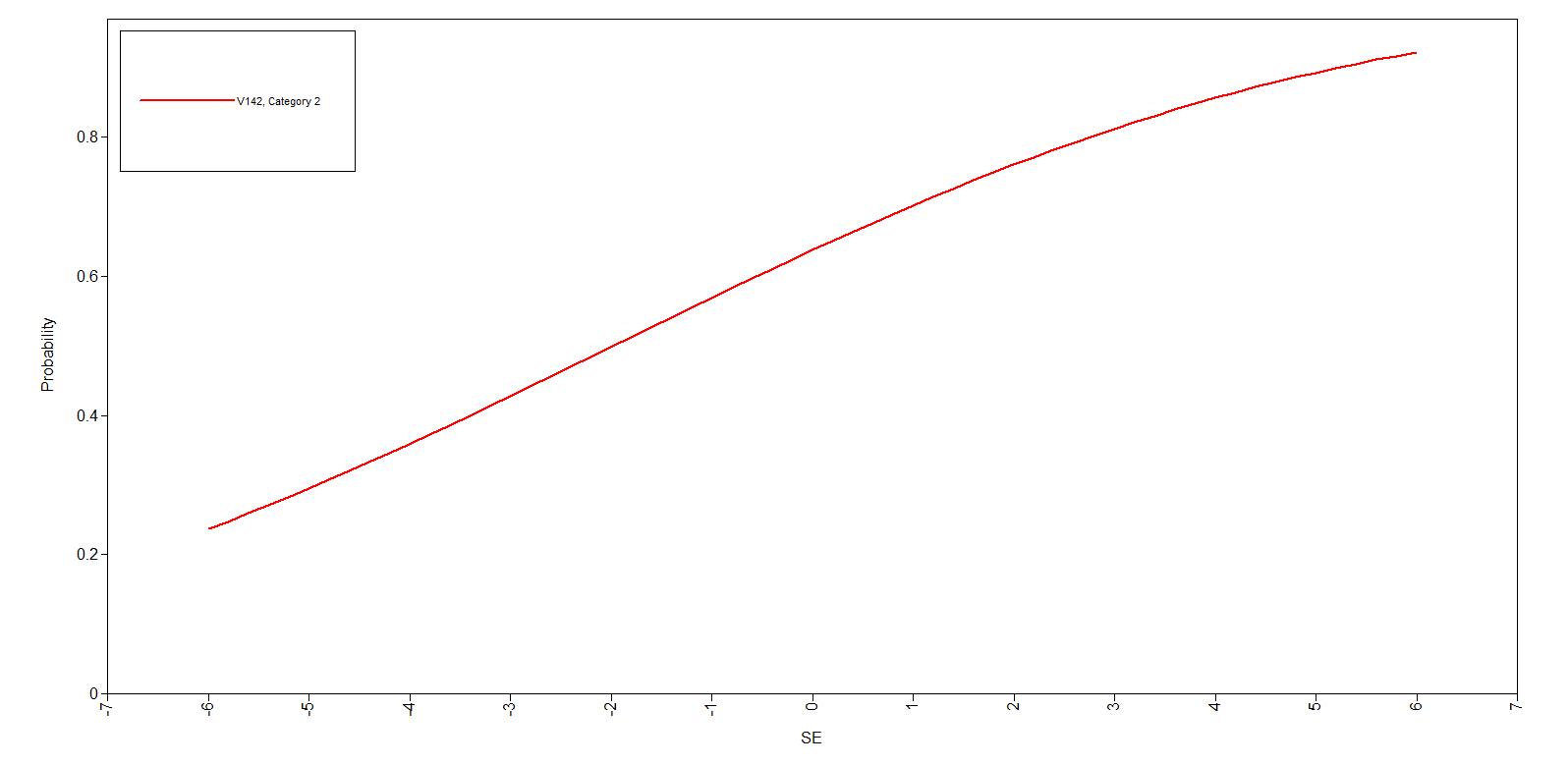
En vigtig pointe i IRT er at adskille egenskaber ved opgaver (items) og egenskaber ved personerne. Der tales om to forskellige egenskaber ved items, deres sværhedsgrad og deres evne til at diskriminere mellem mere og mindre dygtige personer. Dette ses af vedhæftede figur: sværhedsgraden afsættes ud ad x-aksen, og sandsynligheden for at en person besvarer spørgsmålet rigtigt afsættes op ad y-aksen. For et bestemt spørgsmål viser man sammenhængen mellem sværhedsgraden og sandsynligheden for et rigtigt svar ved en kurve (Item Characteristic Curve, iCC). På denne kurve ses diskrimintionsgraden som kurvens stejlhed på det midterste stykke. Jo stejlere kurve, jo større forskel er der i sandsynligheden for et rigtigt svar når man flytter sig lidt på x-aksen. Dette svarer til at spørgsmålet kan skelne melem små forskelle i sværhedsgrad (og den tilsvarende dygtighed hos testpersonen). Det enkelte spørgsmål giver altså information på et bestemt lille stykke af x-aksen. En hel test skal derfor bestå af spørgsmål hvis kurver ligger pænt spredt over hele forløbet af x-aksen, og hver kurve skal være ret stejl.
Her ses et godt diskriminerende item med en stejl kurve
Her ses et dårligt diskriminerende item med en helt flad kurve
Her er en samlet test med en blanding af gode og dårlige items:
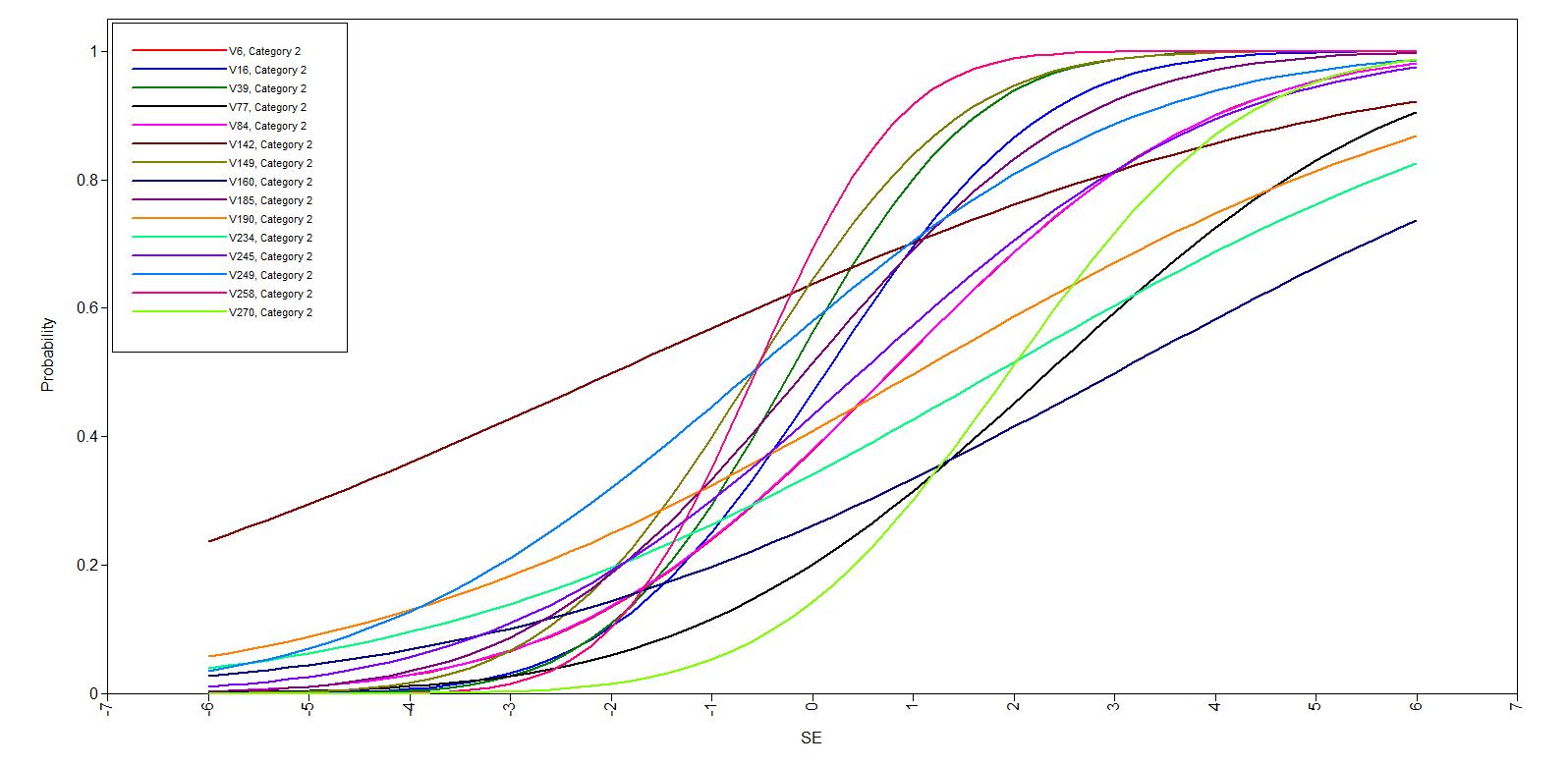
Georg Rasch udviklede en model der kræver at alle spørgsmålene har samme diskriminationsgrad. Rasch-modellen kalders derfor også for en-parametermodellen, hvor altså den eneste parameter angår hvor svær opgaven er. Dette er et ideelt krav som måske kan opfyldes ved færdighedstests, men som sjældent passer ved andre psykologiske tests.
Derfor arbejder man ofte med to-parametermodeller hvor det tillades at spørgsmålene kan have forskellig diskriminationsgrad. F.eks. vil et spørgsmål som ‘fremtiden ser sort ud’ formentlig diskriminere bedre blandt depressive end et spørgsmål som ‘jeg sover for det meste afbrudt om natten’. Der findes også andre IRT-modeller, eksempelvis en tre-parametermodel, der som tredie parameter har en laveste vandret asymptote der afspejler ren gætning på svaret.
Den almindelige praksis i psykologiske tests at lægge resultaterne fra de enkelte items sammen til en sumscore forudsætter en Raschmodel, altså at alle spørgsmålene diskriminerer lige godt. Da dette ofte ikke er tilfældet, sætter det spørgsmålstegn ved brugen af sumscores.
I de senere år er der inden for SEM-paradigmet udviklet metoder der både kan håndtere kategoriale/ordinale og kontinuerte data. Man kan sige at dette har forenet de to retninger Item Response Theory og faktoranalysetraditionen.
Jan Ivanouw
22. maj 2018